现有需求要求查询emp表每个部门工资最高的员工名称、薪水:
第一种实现:
select ename,deptno,sal from emp where (deptno,sal) in (select deptno,max(sal) from emp group by deptno);
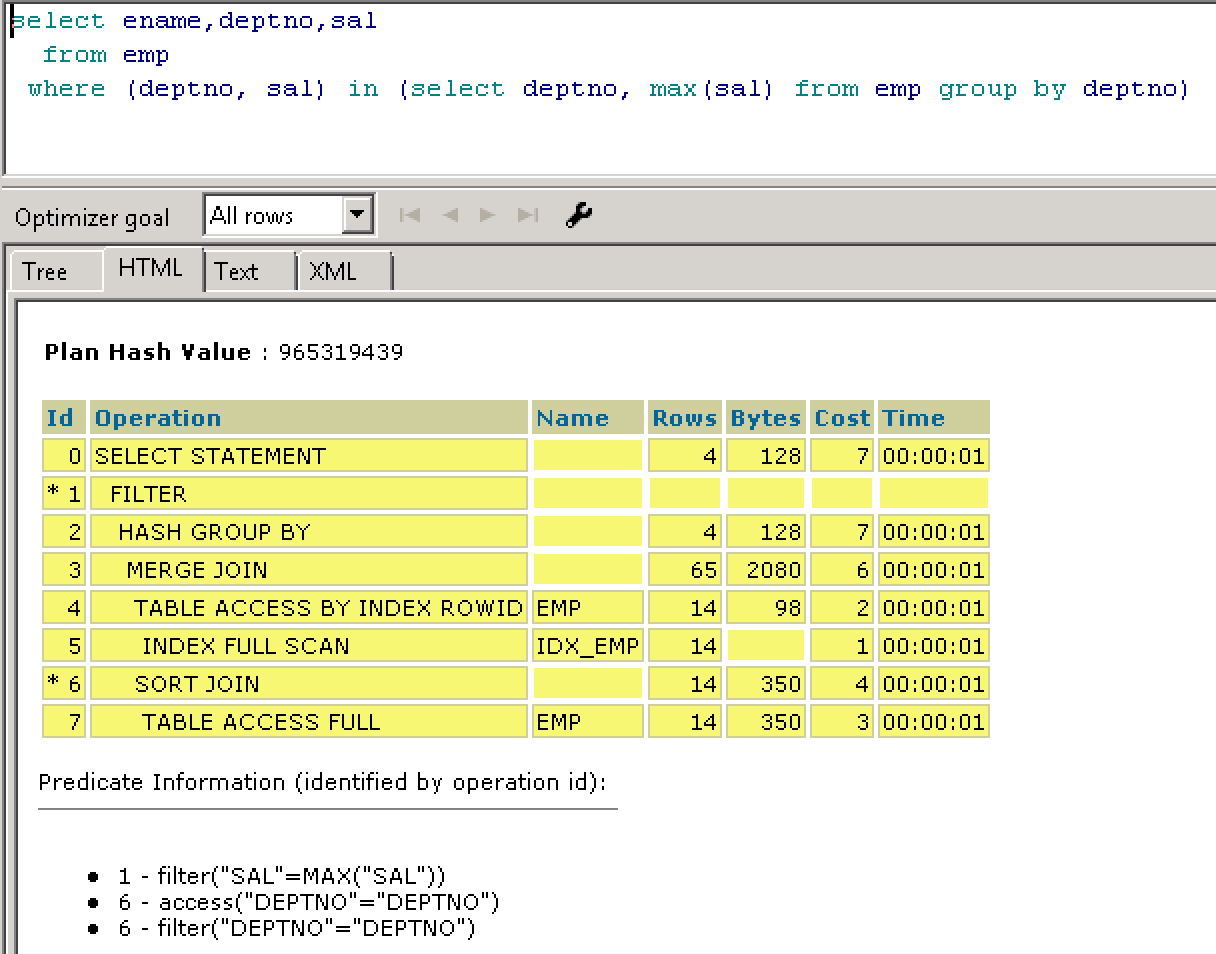
第二种实现:
select ename,e.deptno,e.sal from emp,(select deptno,max(sal) sal from emp group by deptno) e
where e.deptno = emp.deptno and e.sal = emp.sal;
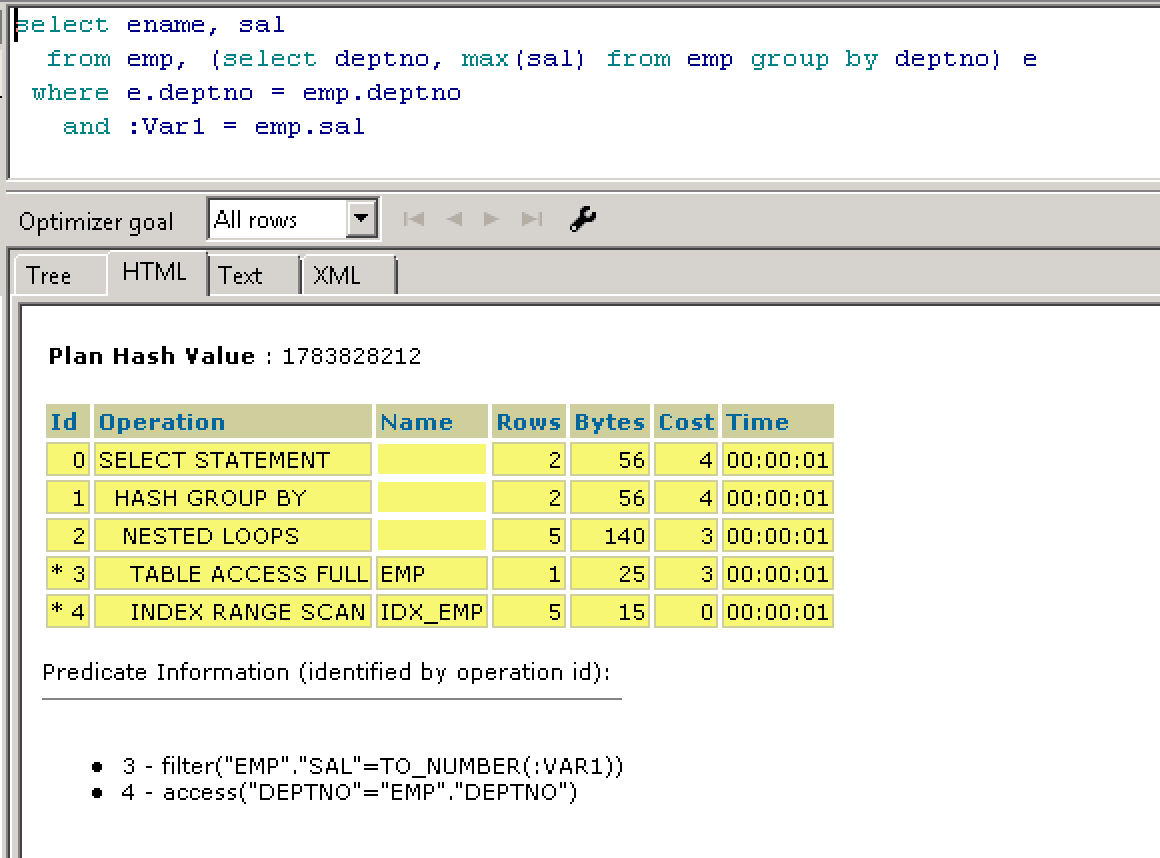
第三种实现:
select ename,deptno,sal from (select ename,sal,deptno,rank() over(partition by deptno order by sal desc) rk
from emp) where rk=1;
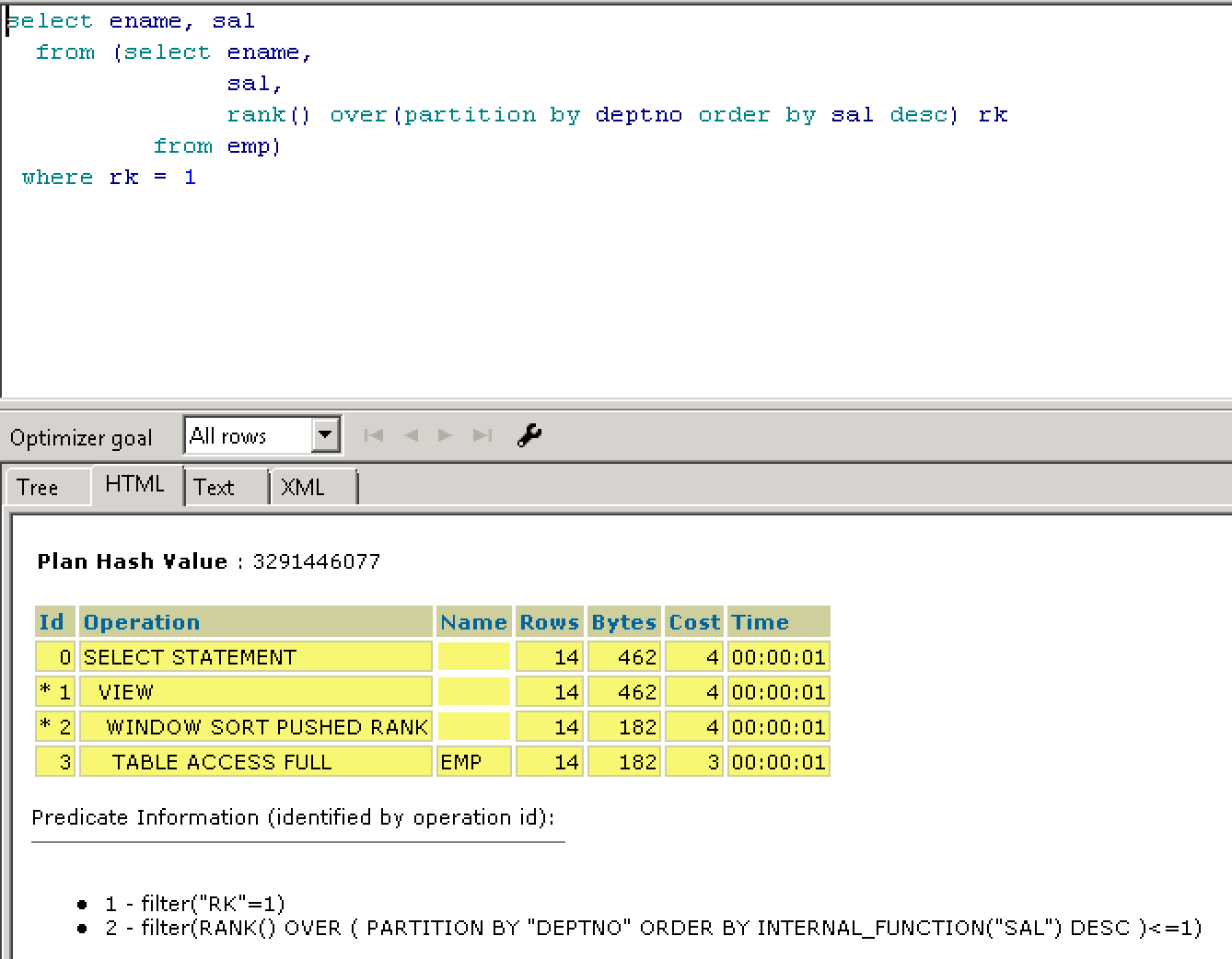
说说今天的正题^_^
简介:over函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行。
写法:over(partition by deptno order by sal) 按照sal排序进行累计,按照class分区。
常用:rank()、dense_rank()可以将所有的都查询出来,rank()是跳跃排序,有两个第二名时接下来是第四名,而dense()是连续排序,有两个第二名时仍然跟着第三名;sum()over()表示根据分组进行求和,也是所有的列都查询出来;first_value()、last_value()分别求出第一个和最后一个信息。
备注:group by与over partition by的区别:group by是对检索结果的保留行进行单纯分组,一般和聚合函数一起使用(avg、sum等),parition by虽然也是分组功能,但是同时也具有其他的高级功能,比如除了统计信息外还可以显示每组的信息。